Available Nested Samplers
Most nested sampling libraries require two things to generate samples from a posterior distribution:
A prior transform converting samples from a uniform distribution to the prior distribution
A log-likelihood function
RadVel’s Posterior object implements both of these through Posterior.prior_transform() and Posterior.likelihood_ns_array(). This means models defined with RadVel can be sampled using pretty much any nested sampling library. For convenience, a few of them have wrappers implemented in the radvel.nested_sampling module:
While these libraries all have a similar APIs, there are small differences in how they should be run and how they generate their outputs. The radvel.nested_sampling module provides a common output format for all libraries, as explained below.
In this notebook, we will demonstrate how to sample a RadVel model with each of these libraries using the K2-24 example dataset from the K2-24 Fitting & MCMC tutorial
Model Definition
First, we need to set up the RadVel model as we would do for MCMC.
[1]:
import time
import radvel
import numpy as np
from pandas import read_csv
import os
from radvel import nested_sampling as rns
import matplotlib.pyplot as plt
/home/vandal/miniforge3/envs/radvel/lib/python3.10/site-packages/docutils/utils/code_analyzer.py:12: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
from pkg_resources import DistributionNotFound as ResourceError
[2]:
# Set to True to avoid re-running samplers
PROCEED = False
OVERWRITE = True
[3]:
def initialize_model():
time_base = 2420
params = radvel.Parameters(2,basis='per tc secosw sesinw logk') # number of planets = 2
params['per1'] = radvel.Parameter(value=20.885258)
params['tc1'] = radvel.Parameter(value=2072.79438)
params['secosw1'] = radvel.Parameter(value=0.01)
params['sesinw1'] = radvel.Parameter(value=0.01)
params['logk1'] = radvel.Parameter(value=1.1)
params['per2'] = radvel.Parameter(value=42.363011)
params['tc2'] = radvel.Parameter(value=2082.62516)
params['secosw2'] = radvel.Parameter(value=0.01)
params['sesinw2'] = radvel.Parameter(value=0.01)
params['logk2'] = radvel.Parameter(value=1.1)
mod = radvel.RVModel(params, time_base=time_base)
mod.params['dvdt'] = radvel.Parameter(value=-0.02)
mod.params['curv'] = radvel.Parameter(value=0.01)
like = radvel.likelihood.RVLikelihood(mod, t, vel, errvel)
like.params['gamma'] = radvel.Parameter(value=0.1, vary=False, linear=True)
like.params['jit'] = radvel.Parameter(value=1.0)
like.params['secosw1'].vary = False
like.params['sesinw1'].vary = False
like.params['per1'].vary = False
like.params['tc1'].vary = False
like.params['secosw2'].vary = False
like.params['sesinw2'].vary = False
like.params['per2'].vary = False
like.params['tc2'].vary = False
post = radvel.posterior.Posterior(like)
post.priors += [radvel.prior.Gaussian('jit', np.log(3), 0.5)]
post.priors += [radvel.prior.Gaussian('logk1', np.log(5), 10)]
post.priors += [radvel.prior.Gaussian('dvdt', 0, 1.0)]
post.priors += [radvel.prior.Gaussian('curv', 0, 1e-1)]
post.priors += [radvel.prior.Gaussian('logk2', np.log(5), 10)]
return post
[4]:
path = os.path.join(radvel.DATADIR,'epic203771098.csv')
rv = read_csv(path)
t = np.array(rv.t)
vel = np.array(rv.vel)
errvel = rv.errvel
ti = np.linspace(rv.t.iloc[0]-5,rv.t.iloc[-1]+5,100)
[5]:
post = initialize_model()
print(post)
parameter value vary
per1 20.8853 False
tc1 2072.79 False
secosw1 0.01 False
sesinw1 0.01 False
logk1 1.1 True
per2 42.363 False
tc2 2082.63 False
secosw2 0.01 False
sesinw2 0.01 False
logk2 1.1 True
dvdt -0.02 True
curv 0.01 True
gamma 0.1 False
jit 1 True
tp1 2070.18
e1 0.0002
w1 0.785398
k1 3.00417
tp2 2077.33
e2 0.0002
w2 0.785398
k2 3.00417
Priors
------
Gaussian prior on jit, mu=1.0986122886681096, sigma=0.5
Gaussian prior on logk1, mu=1.6094379124341003, sigma=10
Gaussian prior on dvdt, mu=0, sigma=1.0
Gaussian prior on curv, mu=0, sigma=0.1
Gaussian prior on logk2, mu=1.6094379124341003, sigma=10
[6]:
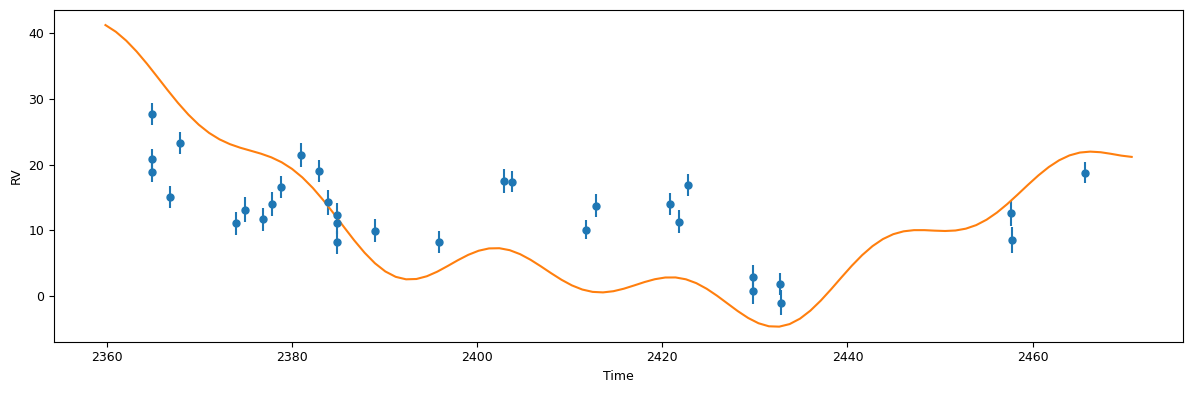
def plot_results(like):
fig = plt.figure(figsize=(12,4))
fig = plt.gcf()
fig.set_tight_layout(True)
plt.errorbar(
like.x, like.model(t)+like.residuals(),
yerr=like.yerr, fmt='o'
)
plt.plot(ti, like.model(ti))
plt.xlabel('Time')
plt.ylabel('RV')
return fig
[7]:
plot_results(post.likelihood)
plt.show()
Nested Sampling
Now that we have our model, we can run one or more nested sampling algorithms. Here we run all libraries available in RadVel. Each library has its own nested_sampling.run_<library_name>() methods.
In their simplest form, all these methods require only a Posterior as input. However, arguments can be passed directly to the samplers or the “run” functions through sampler_kwargs and run_kwargs, respectively. We refer users to the documentation of each library (linked at the start of this notebook) to find out which arguments are available.
Each nested sampling function will return results in a standard dictionary format with the following keys:
samples: equally-weighted samples (equivalent to MCMC samples). The samples also include anlnprobabilitycolumn, for consistency with the MCMC interface.lnZ: Natural log of the Bayesian evidencelnZerr: Statistical uncertainty on the evidencesampler: Sampler object from the underlying nested sampling package, providing acces to more details about the run and its extra outputs. This is not available for PyMultiNest, which stores the outputs on disk instead of in a Python object.
Running the samplers
Let us now run all available samplers and see how they perform.
[8]:
multinest_start = time.time()
multinest_results = rns.run(post, sampler="multinest", output_dir="multinest_demo", proceed=PROCEED, overwrite=OVERWRITE)
multinest_time = time.time() - multinest_start
print(f"Running multinest took {multinest_time / 60:.2f} min")
*****************************************************
MultiNest v3.10
Copyright Farhan Feroz & Mike Hobson
Release Jul 2015
no. of live points = 400
dimensionality = 5
*****************************************************
analysing data from multinest_demo/out.txt ln(ev)= -102.44719426706034 +/- 0.20587852822593408
Total Likelihood Evaluations: 21919
Sampling finished. Exiting MultiNest
Running multinest took 0.32 min
[9]:
dynesty_start = time.time()
dynesty_results = rns.run(post, sampler="dynesty-static", output_dir="dynesty_demo", proceed=PROCEED, overwrite=OVERWRITE)
dynesty_time = time.time() - dynesty_start
print(f"Running dynesty took {dynesty_time / 60:.2f} min")
iter: 10799 | +500 | bound: 1410 | nc: 1 | ncall: 1075955 | eff(%): 1.051 | loglstar: -inf < -82.470 < inf | logz: -103.429 +/- nan | dlogz: 0.001 > 0.509
Running dynesty took 15.31 min
[10]:
dynesty_start = time.time()
dynesty_dynamic_results = rns.run(post, sampler="dynesty-dynamic", output_dir="dynesty_demo_dynamic", proceed=PROCEED, overwrite=OVERWRITE)
dynesty_time = time.time() - dynesty_start
print(f"Running dynesty took {dynesty_time / 60:.2f} min")
iter: 21418 | batch: 5 | bound: 38 | nc: 1 | ncall: 1425431 | eff(%): 1.492 | loglstar: -89.495 < -82.594 < -83.899 | logz: -103.194 +/- 0.133 | stop: 0.798
Running dynesty took 21.37 min
[11]:
ultranest_start = time.time()
# Ultranest does not accept False for "resume"
ultranest_results = rns.run(post, sampler="ultranest", output_dir="ultranest_demo", proceed=PROCEED, overwrite=OVERWRITE)
ultranest_time = time.time() - ultranest_start
print(f"Running ultranest took {ultranest_time / 60:.2f} min")
[ultranest] Sampling 400 live points from prior ...
[ultranest] Explored until L=-8e+01 8 [-82.8705..-82.8701]*| it/evals=10099/269614 eff=3.7513% N=400 0 00 0
[ultranest] Likelihood function evaluations: 269614
[ultranest] Writing samples and results to disk ...
[ultranest] Writing samples and results to disk ... done
[ultranest] logZ = -103.4 +- 0.1932
[ultranest] Effective samples strategy satisfied (ESS = 2740.8, need >400)
[ultranest] Posterior uncertainty strategy is satisfied (KL: 0.46+-0.07 nat, need <0.50 nat)
[ultranest] Evidency uncertainty strategy is satisfied (dlogz=0.19, need <0.5)
[ultranest] logZ error budget: single: 0.21 bs:0.19 tail:0.01 total:0.19 required:<0.50
[ultranest] done iterating.
Running ultranest took 4.17 min
[12]:
nautilus_start = time.time()
nautilus_results = rns.run(post, sampler="nautilus", output_dir="nautilus_demo", proceed=PROCEED, run_kwargs={"verbose": True}, overwrite=OVERWRITE)
nautilus_time = time.time() - nautilus_start
print(f"Running nautilus took {nautilus_time / 60:.2f} min")
Starting the nautilus sampler...
Please report issues at github.com/johannesulf/nautilus.
Status | Bounds | Ellipses | Networks | Calls | f_live | N_eff | log Z
Finished | 36 | 1 | 4 | 81100 | N/A | 19922 | -103.33
Running nautilus took 5.81 min
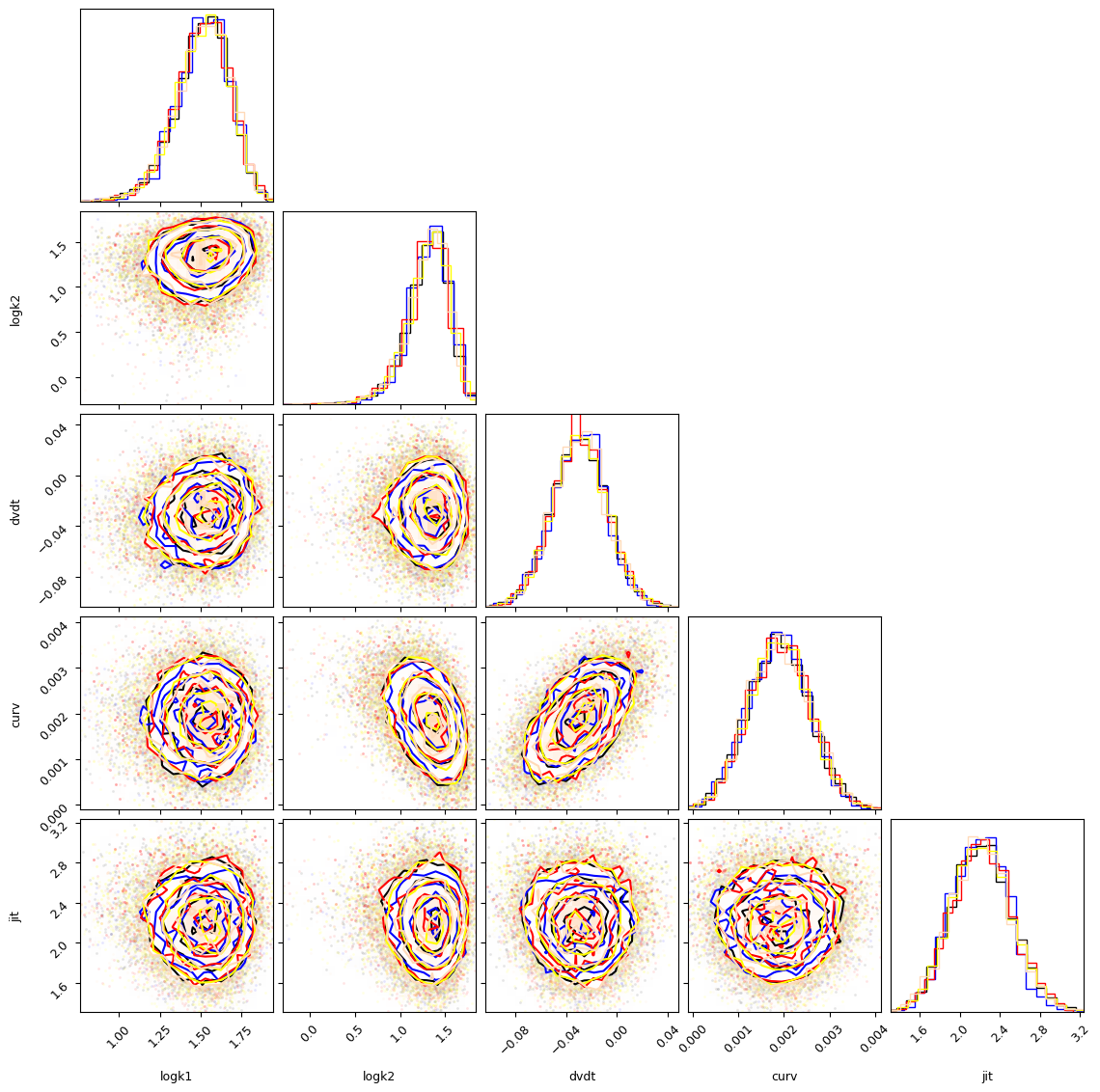
Once we have all the results, we can compare the Bayesian evidence and the posterior distributions to make sure they are consistent between samplers. Keep in mind that nested sampling algorithms will perform differently on different problems. Both speed and accuracy will depend on the number of dimensions (parameters) and the exact choice of settings. See Buchner (2021) for a review of this topic.
[13]:
print(f"Multinest: {multinest_results['lnZ']:.2f} +/- {multinest_results['lnZerr']:.2f}")
print(f"Dynesty (static): {dynesty_results['lnZ']:.2f} +/- {dynesty_results['lnZerr']:.2f}")
print(f"Dynesty (dynamic): {dynesty_dynamic_results['lnZ']:.2f} +/- {dynesty_dynamic_results['lnZerr']:.2f}")
print(f"Ultranest: {ultranest_results['lnZ']:.2f} +/- {ultranest_results['lnZerr']:.2f}")
print(f"Nautilus: {nautilus_results['lnZ']:.2f} +/- {nautilus_results['lnZerr']:.2f}")
Multinest: -103.13 +/- 0.06
Dynesty (static): -103.43 +/- 0.33
Dynesty (dynamic): -103.18 +/- 0.12
Ultranest: -103.38 +/- 0.49
Nautilus: -103.33 +/- 0.01
[14]:
import corner
hist_kwargs = {"density": True}
fig = corner.corner(nautilus_results["samples"].values[:, :-1], labels=post.name_vary_params(),range=np.repeat(0.999, len(post.name_vary_params())), hist_kwargs=hist_kwargs)
corner.corner(multinest_results["samples"].values[:, :-1], color="b", fig=fig, hist_kwargs=hist_kwargs | {"color": "b"})
corner.corner(dynesty_results["samples"].values[:, :-1], color="r", fig=fig, hist_kwargs=hist_kwargs | {"color": "r"},range=np.repeat(0.999, len(post.name_vary_params())))
corner.corner(dynesty_dynamic_results["samples"].values[:, :-1], color="yellow", fig=fig, hist_kwargs=hist_kwargs | {"color": "yellow"},range=np.repeat(0.999, len(post.name_vary_params())))
corner.corner(ultranest_results["samples"].values[:, :-1], color="peachpuff", fig=fig, hist_kwargs=hist_kwargs | {"color": "peachpuff"}, range=np.repeat(0.999, len(post.name_vary_params())))
plt.show()